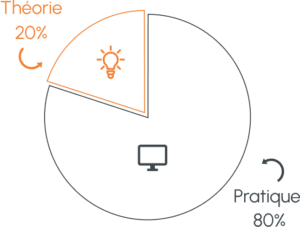

Une formation flexible 100% en ligne
Démarrez à tout moment votre nouvelle carrière ! Disponible à temps partiel ? Pas de problème, étudiez à votre rythme.
Des projets professionnalisants
Vous développerez vos compétences professionnelles en travaillant sur des projets concrets inspirés de la réalité en entreprise.Pas de problème, étudiez à votre rythme.
Un accompagnement personnalisé
Bénéficiez de sessions de mentorat hebdomadaires avec un expert du métier.
")
Gagnez des certificats et des diplômes
Gagner des certificats et des diplômes peut améliorer votre carrière, élargir vos horizons et vous offrir une satisfaction personnelle accrue.